
AI 编程智能体配置实战:如何为每个角色选择最合适的模型
用 AI 编程工具写代码不难,但让多个 AI 智能体像一支真正的工程团队一样协作——这需要精心配置。本文分享我如何基于 OhMyOpenCode(omo)为 Claude Code 的每个智能体角色选择最合适的国产模型,以及背后的选型逻辑。
前言
我日常使用 Claude Code(通过 Anthropic 代理接入国产大模型)进行开发,配合 OhMyOpenCode 插件来管理智能体(Agent)的模型分配。这套配置已经稳定运行了几个月,覆盖了从代码探索、架构咨询到前端实现、文档写作的全流程。
核心思路很简单:不同任务需要不同的”思维方式”,而不同模型有不同的擅长领域。把对的模型放在对的角色上,整个系统的效率和质量会有质的飞跃。
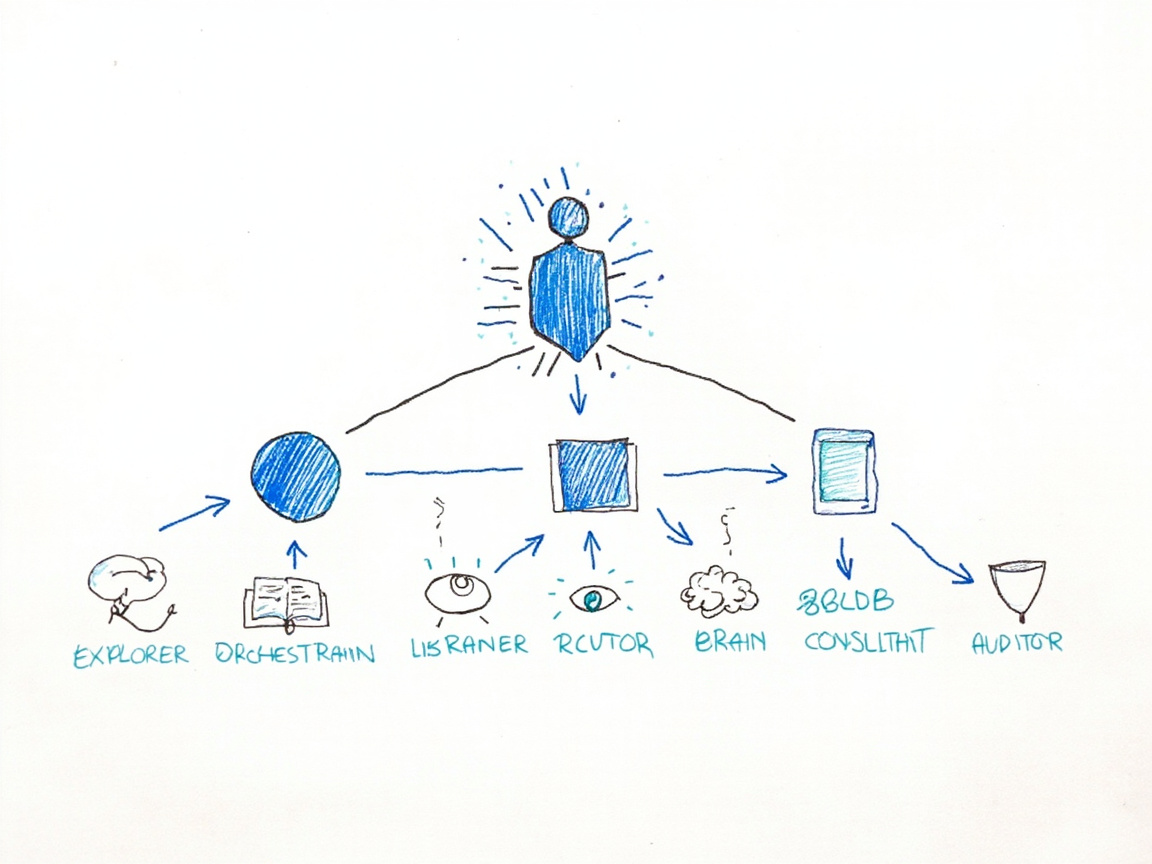
图1:智能体协作架构总览
我的模型阵容
先交代一下我用的模型全家桶,全部通过 Anthropic 兼容协议接入:
| 模型 | 厂商 | 核心特点 |
|---|---|---|
| GLM-5.1 | 智谱 AI | 综合能力强,逻辑推理稳健,中文理解出色 |
| GLM-5-turbo | 智谱 AI | GLM-5.1 的快速版本,响应极快 |
| Qwen3.5-plus | 阿里巴巴 | 代码生成质量高,实现细节把控好 |
| MiniMax-M2.7 | MiniMax | 性价比极高,响应速度快,适合轻量任务 |
| Kimi-k2.5 | Moonshot | 长上下文理解优秀,创意表达和视觉理解强 |
| GPT-5.4 | OpenAI | 推理天花板,复杂问题处理能力最强(通过国际通道) |
智能体配置详解
1. Sisyphus(主编排者)→ GLM-5.1
Sisyphus 是整个系统的”大脑”,负责接收用户请求、拆解任务、分配给子智能体、汇总结果。它需要:
- 全局视野:理解整个任务的上下文和依赖关系
- 判断力:决定哪些任务可以并行、哪些需要串行
- 中文沟通:与用户用中文交互,需要优秀的中文理解
为什么选 GLM-5.1:智谱的 GLM-5.1 在中文理解和复杂推理上表现稳定,作为主编排者需要的是”不犯大错”而不是”偶尔惊艳”。GLM-5.1 的稳健性让它在编排场景下值得信赖。
2. Prometheus(实现执行者)→ Qwen3.5-plus
Prometheus 负责将方案转化为代码。它需要:
- 代码质量:生成的代码要能直接用,不是伪代码
- 细节把控:变量命名、边界处理、异常处理都要到位
- 框架理解:熟悉 Spring Boot、MyBatis、React 等主流框架
为什么选 Qwen3.5-plus:阿里的 Qwen 系列在代码生成上一直是国产模型的第一梯队。Qwen3.5-plus 在代码补全、重构、Bug 修复等场景下表现出色,尤其是 Java 和 TypeScript 生态的理解深度。
3. Oracle(架构顾问)→ GLM-5.1
Oracle 是只读的高质量顾问,在遇到架构决策、复杂 Bug、安全问题时才被咨询。它需要:
- 深度推理:分析复杂系统间的 tradeoff
- 表达清晰:把复杂问题解释得通俗易懂
- 不输出代码:只给建议,不动手
为什么选 GLM-5.1:Oracle 的核心能力是”想清楚”而不是”写得快”。GLM-5.1 的推理链路清晰,回答结构化程度高,适合做顾问角色。与 Sisyphus 使用同一模型也保证了思维一致性。
4. Hephaestus(高质量实现)→ GPT-5.4
Hephaestus 是”精工细作”的实现者,配置为 high variant,只在需要高质量输出时才启用。它需要:
- 顶级代码质量:架构清晰、设计模式正确、测试完备
- 复杂问题解决:处理多系统交互、性能优化等高难度任务
为什么选 GPT-5.4:在推理天花板这个维度上,GPT-5.4 仍然是目前最强的。对于 Hephaestus 这种”压箱底”的角色,用最强的模型确保关键时刻不掉链子。虽然成本更高,但只在必要时调用。
图2:各模型在推理深度、代码质量、响应速度、性价比四个维度的定位
5. Explore(代码探索)→ MiniMax-M2.7
Explore 负责在代码库中搜索模式、理解代码结构。它的工作模式是”大量并发搜索 + 快速总结”。它需要:
- 快速响应:经常被并行调用 2-5 个实例
- 足够准确:不需要完美,但不能遗漏关键信息
- 低成本:调用频率最高
为什么选 MiniMax-M2.7:Explore 是整个系统里调用频率最高的智能体,可能一个任务就要并行启动 3-5 个。MiniMax-M2.7 的响应速度和性价比让它成为这种”量大队”角色的最佳选择。
6. Librarian(外部参考搜索)→ MiniMax-M2.7
Librarian 负责搜索外部文档、查找开源实现示例、检索 API 文档。与 Explore 类似:
- 高并发:经常与 Explore 同时启动
- 搜索导向:核心能力是”找到”而不是”深度分析”
为什么选 MiniMax-M2.7:与 Explore 同理,Librarian 也是高频调用的搜索型智能体,性价比和速度优先。
7. Metis(预规划分析)→ GLM-5-turbo
Metis 在复杂任务开始前分析需求,识别隐藏意图和模糊点。它需要:
- 快速响应:任务是”想清楚再动手”,不能等太久
- 分析能力:识别需求中的矛盾、遗漏和风险
- 足够准确:预规划不需要 100% 完美,够用就行
为什么选 GLM-5-turbo:Metis 的工作是”快速扫描”而不是”深度分析”。GLM-5-turbo 的快速响应特性让预规划不会成为瓶颈,同时保留了足够的分析能力。
8. Momus(计划审查)→ GPT-5.4
Momus 是”挑剔的审查官”,负责评审工作计划的质量、完整性和可执行性。它需要:
- 高标准:能发现计划中的模糊点、遗漏和风险
- 逻辑严密:审查需要滴水不漏
- 不怕得罪人:直说问题,不糊弄
为什么选 GPT-5.4:审查需要的是”吹毛求疵”的能力,GPT-5.4 在发现逻辑漏洞和隐含假设方面表现最强。用最强的模型做审查,确保每个计划在执行前都经得起推敲。
9. Multimodal Looker(视觉理解)→ Kimi-k2.5
负责分析图片、截图、UI 设计稿等视觉内容。它需要:
- 视觉理解:准确识别图片中的文字、布局、组件
- 设计感知:理解 UI 设计意图
- 中文 OCR:识别中文截图中的代码和文字
为什么选 Kimi-k2.5:Kimi 在多模态理解上,尤其是中文场景下的视觉理解表现突出。对中文截图、设计稿的识别准确率高。
任务类别配置
除了固定角色的智能体,OhMyOpenCode 还支持按任务类别分配模型。我按”任务复杂度 × 任务领域”来分配:
| 类别 | 模型 | 选型理由 |
|---|---|---|
| deep(深度实现) | GLM-5.1 | 需要综合推理能力,稳健可靠 |
| ultrabrain(超脑) | GLM-5.1 | 逻辑推理密集型任务 |
| quick(快速任务) | MiniMax-M2.7 | 单文件修改,速度优先 |
| unspecified-low | MiniMax-M2.7 | 低复杂度通用 |
| unspecified-high | GLM-5.1 | 高复杂度通用 |
| visual-engineering(前端) | Kimi-k2.5 | 视觉理解 + 创意设计 |
| artistry(创意方案) | Kimi-k2.5 | 非常规问题需要创意思维 |
| writing(文档写作) | Kimi-k2.5 | 长文输出,表达流畅 |
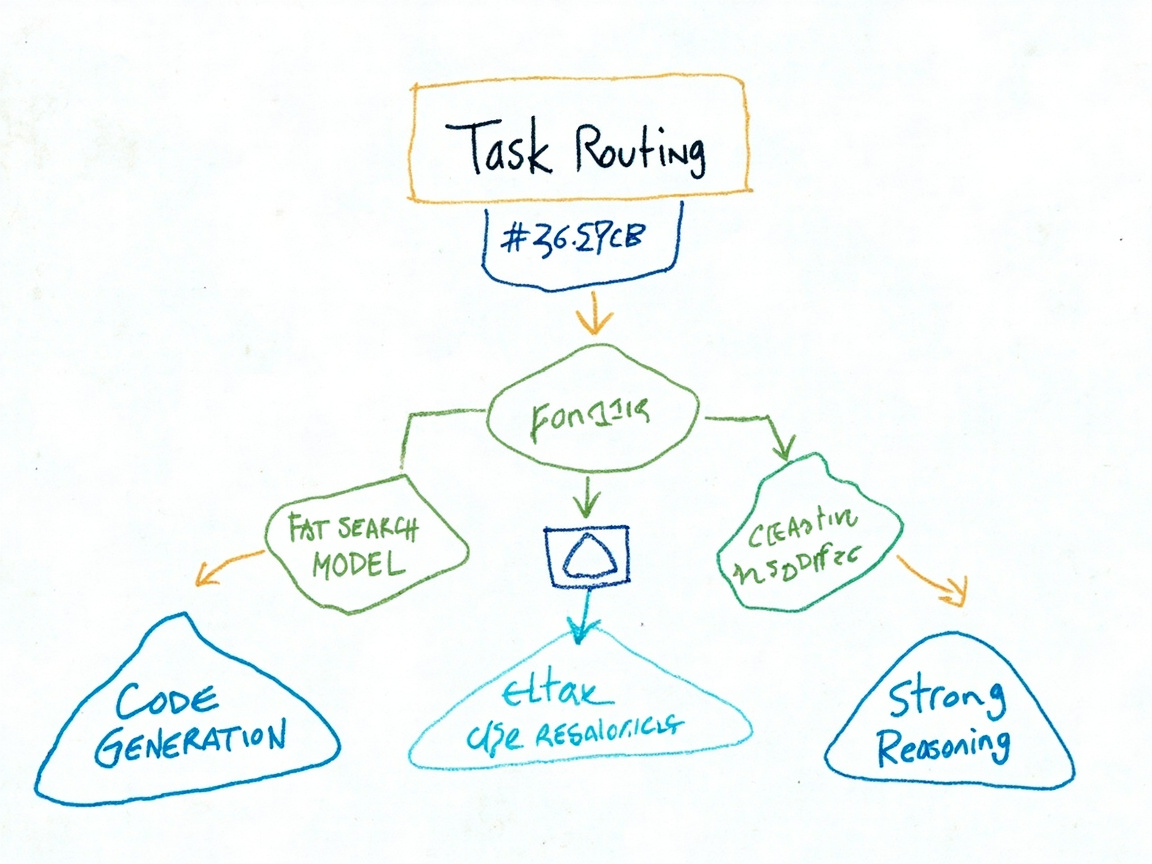
图3:任务类别到模型的分配决策流程
分配逻辑总结:
- GLM-5.1:逻辑推理、架构决策、深度实现 → “稳重派”
- MiniMax-M2.7:高频搜索、快速任务、低复杂度 → “效率派”
- Kimi-k2.5:前端视觉、创意写作、多模态 → “创意派”
- Qwen3.5-plus:代码生成、Bug 修复、重构 → “实干派”
- GPT-5.4:计划审查、高质量实现 → “天花板”
完整配置文件
以下是 oh-my-opencode.json 的完整配置:
1 | { |
附加配置:插件与 MCP
除了模型分配,我还配置了一些插件来增强能力:
| 插件 | 作用 |
|---|---|
| Superpowers | 提供 TDD、调试、计划编写等工程化工作流 |
| Claude HUD | 终端状态栏,实时显示智能体活动 |
| JDTLS-LSP | Java 语言服务器,精准的代码智能 |
| Skill Creator | 自定义技能创建器 |
| Minimax Skills | MiniMax 图片生成、Web 搜索等 |
| Ralph Loop | 自动化循环执行 |
MCP 服务:配置了 MySQL MCP 服务器,让智能体可以直接查询数据库,在处理数据相关的开发任务时非常方便。
自定义 Agent:我还创建了一个 java-bug-pathfinder 自定义智能体,专门用于 Java Bug 的调用链追踪和根因分析,配置为只读权限,确保安全。
选型总结与建议
经过几个月的使用,我总结出以下选型原则:
编排类角色选稳不选猛:主编排者需要的是可靠性和全局视野,不需要偶尔的天才表现。GLM-5.1 的稳健特质完美匹配。
高频角色选快不选强:Explore、Librarian 这种可能并行启动 5 个实例的角色,响应速度和成本比”聪明程度”更重要。MiniMax-M2.7 是这个场景的最优解。
审查角色选强不选快:Momus 做 Plan Review,宁可多等几秒也要找出问题。GPT-5.4 的审查质量值得这点等待。
创意角色选长不选短:前端设计、文档写作需要长上下文和创意表达。Kimi-k2.5 的长文本和视觉理解能力让它在这个领域领先。
实现角色选专不选全:代码生成需要的是对框架和语言的深度理解。Qwen3.5-plus 在代码领域的专精让它在 Prometheus 角色上表现突出。
按预算分层:不是每个任务都需要最贵的模型。把高成本模型留给 Hephaestus 和 Momus 这种”关键时刻才上场”的角色,日常任务用性价比模型。
结语
AI 编程工具的配置不是”选一个最强模型就完事”。就像组建一个工程团队,你需要了解每个”成员”的特长,把合适的人放在合适的位置。希望这篇分享能帮助你更好地配置自己的 AI 编程智能体团队。
如果你也在用 Claude Code + OhMyOpenCode,欢迎交流你的配置方案。