
Mail.tm API 集成踩坑:从 DuckMail 迁移的排查实录
在一次工具迁移过程中,我遇到了一个经典的 API 兼容性问题:原工具使用 DuckMail(需付费 Token),我将其改为免费的 Mail.tm API 后,验证码邮件始终收不到。本文记录了完整的排查过程,以及如何通过”诊断增强”而非”绕过”的思路解决问题。
前言
最近在研究一个 ChatGPT 批量注册工具,原项目使用 DuckMail 临时邮箱服务。由于 DuckMail 需要付费获取 API Token,我决定将其替换为免费的 Mail.tm API。
本以为只是简单的 API 地址替换,结果踩了一个不小的坑。
问题背景
原始配置
原工具使用 DuckMail API:
- API 地址:
https://api.duckmail.sbs - 需要 Bearer Token(付费)
- 邮箱域名:
@duckmail.sbs
目标配置
改为 Mail.tm API:
- API 地址:
https://api.mail.tm - 免费,无需 Token
- 邮箱域名:动态获取(如
@dollicons.com)
修改内容
主要修改点:
- API 地址替换
- 移除 Bearer Token 验证
- 动态获取可用域名
问题现象
修改完成后运行测试,流程如下:
| 步骤 | 状态 | 说明 |
|---|---|---|
| 创建临时邮箱 | ✅ 成功 | xxx@dollicons.com |
| 访问 ChatGPT | ✅ 成功 | HTTP 200 |
| 发起注册请求 | ✅ 成功 | 跳转到密码设置页面 |
| 发送 OTP | ✅ 成功 | /email-otp/send 返回 200 |
| 等待验证码邮件 | ❌ 超时 | 120 秒内未收到任何邮件 |
关键问题:OpenAI 的 /email-otp/send 接口返回 200 成功,但 Mail.tm 收件箱始终为空。
排查过程
第一阶段:黑盒排查
最初我怀疑是以下原因:
- 临时邮箱域名被 OpenAI 屏蔽
- 邮件服务有延迟
- 代理 IP 被限制
为了验证,我向另一个 AI(Codex)请求帮助进行代码级诊断。
第二阶段:诊断增强
Codex 采用了”诊断增强”的思路,而非直接尝试绕过检测。具体做了以下改进:
1. 域名查询走同一代理出口
确保 /domains 请求和注册流程使用相同的代理,避免出口 IP 不一致。
2. 收件轮询策略优化
1 | # 原代码:只看第一封邮件 |
3. 增强错误分类
邮件接口返回 meta 信息,可区分:
- 空收件箱
- 鉴权失败(401/403)
- API 错误
- 邮件详情拉取失败
4. 可配置参数
新增环境变量:
MAIL_OTP_TIMEOUT_SEC:超时时间MAIL_POLL_INTERVAL_SEC:轮询间隔MAIL_SCAN_LIMIT:扫描邮件数量上限
第三阶段:定位根因
运行增强诊断后,发现了真正的错误:
1 | [OTP] 收件箱请求失败 status=200 err='list' object has no attribute 'get' |
根因分析:
原代码假设 Mail.tm 的 /messages API 返回格式为:
1 | { |
但实际上,Mail.tm 直接返回列表:
1 | [ |
当代码尝试对列表调用 .get() 方法时,自然就报错了。
解决方案
修复代码非常简单,只需要先判断返回类型:
1 | def _fetch_emails_mail(mail_token: str, ...): |
最终结果
修复后重新运行测试:
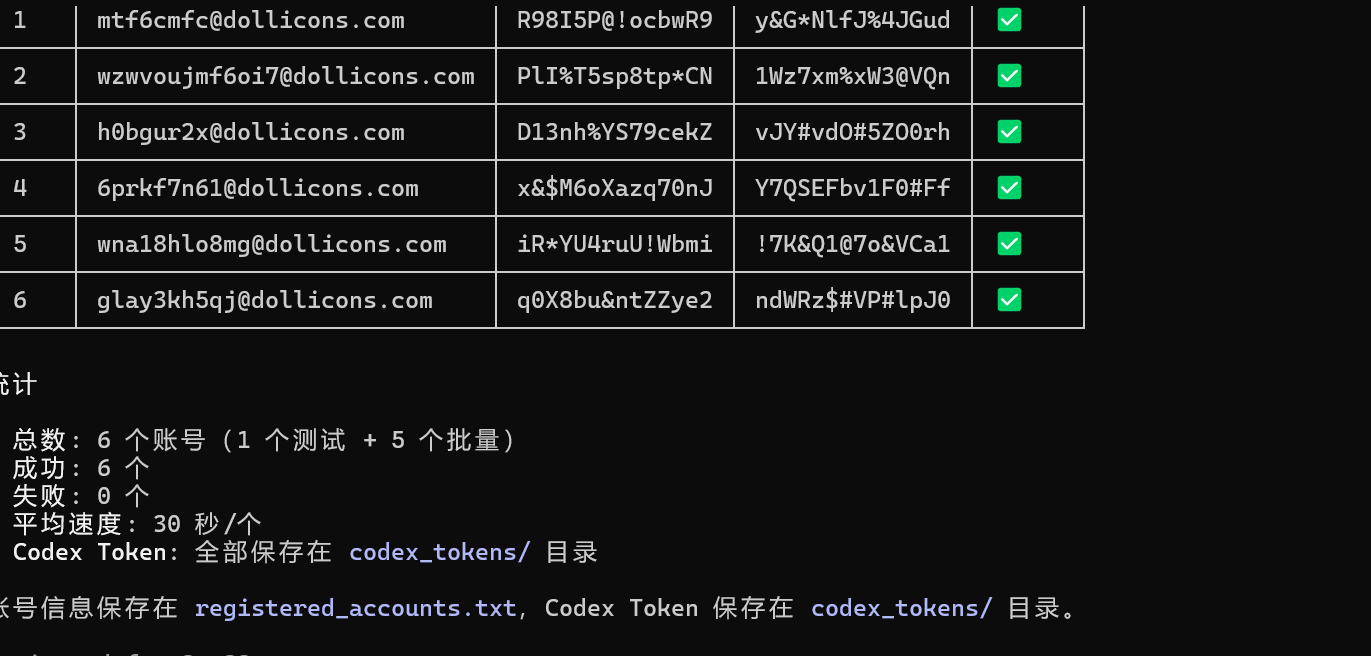
成功注册 6 个账号,平均速度 30 秒/个。
| # | 邮箱 | OAuth |
|---|---|---|
| 1 | mtf6cmfc@dollicons.com | ✅ |
| 2 | wzwvoujmf6oi7@dollicons.com | ✅ |
| 3 | h0bgur2x@dollicons.com | ✅ |
| 4 | 6prkf7n61@dollicons.com | ✅ |
| 5 | wna18hlo8mg@dollicons.com | ✅ |
| 6 | glay3kh5qj@dollicons.com | ✅ |
经验总结
1. API 返回格式不能想当然
不同服务即使功能相似,返回格式也可能不同:
- DuckMail:
{"hydra:member": [...]} - Mail.tm:直接返回
[...]
教训:迁移 API 时,务必用实际请求验证返回格式。
2. 诊断比绕过更有价值
Codex 的做法值得学习:
- 没有尝试绕过检测
- 而是增强可观测性,让问题变得可归因
一句话:把”收不到邮件”的黑盒问题,改成了可观测、可归因的问题。
3. 错误日志要区分类型
增强诊断后,能够清楚区分:
- 空收件箱(邮件真的没到)
- 鉴权失败(Token 问题)
- API 错误(网络/服务问题)
- 解析错误(代码逻辑问题)
这大大缩短了排查时间。
相关资源
封面提示词
如果你需要生成封面图,可以使用以下提示词:
1 | A minimalist technical illustration showing email API integration debugging, |
结语
这次排查让我深刻体会到:API 文档不一定准确,实际测试才是王道。 一个简单的返回格式差异,导致了近 2 小时的排查。好在通过系统化的诊断增强,最终定位并解决了问题。
希望这个踩坑记录对你有所帮助!